A Conversational AI Assistant for BeagleBoard using RAG and Fine-tuning - Fayez Zouari#
Introduction#
Summary links#
Contributor: Fayez Zouari
Mentors: Jason Kridner, Aryan Nanda, Kumar Abhishek
Code: BeagleMind
Documentation: BeagleMind Forum Thread
Status#
This project is currently just a proposal.
Proposal#
Created accounts across OpenBeagle and Beagle Forum
The PR Request for Cross Compilation: #197
Created a project proposal using the proposed template.
About#
Forum: FAYEZ_ZOUARI
OpenBeagle: fayezzouari
Discord ID: .kageyamo
GitHub: fayezzouari
School: INSAT (National Institute of Applied Science and Technology)
Country: Tunisia
Typical work hours: 9:00 AM - 6:00 PM (UTC+1)
Previous GSoC participation: No
Project#
Project name: BeagleMind - Documentation Assistant with Fine-tuned LLM and RAG
Description#
BeagleMind combines fine-tuned LLMs with RAG to create an accurate documentation assistant that:
Uses PEFT/LoRA fine-tuning on BeagleBoard documentation
Implements RAG for fact-based responses and to reduce LLM hallucination
Accessed using a HF inference endpoint
Deploys via: - CLI tool for local usage - Web interface with websockets
Includes agentic evaluation framework
Technical Implementation#
LLM Fine-tuning Architecture#
The system will employ the selected LLM as its base model, utilizing Parameter-Efficient Fine-Tuning (PEFT) with LoRA adapters to specialize the model for BeagleBoard documentation. The training pipeline processes OpenBeagle resources through:
Semantic segmentation of technical documentation
Generation of instruction-response pairs
Dynamic masking of code samples for focused learning
Evaluation will combine:
Perplexity measurements on held-out documentation
Task-specific accuracy on BeagleBoard API questions
Human review of generated troubleshooting steps
RAG Integration Pipeline#
The retrieval-augmented generation system implements a three-stage accuracy enforcement:
Document Processing:
Hierarchical chunking preserving code-sample context
Metadata enrichment with section headers
Cross-document relationship mapping
Vector Retrieval:
Hybrid dense-sparse retrieval using BAAI embeddings
Query-adaptive reranking
Confidence-based fallback mechanisms
Response Generation:
Contextual grounding with retrieved passages
Automatic citation injection
Confidence thresholding for uncertain responses
Hosting Infrastructure#
The production deployment features:
Component |
Implementation |
|---|---|
Inference Endpoint |
Hugging Face TGI with 4-bit quantization |
Load Balancing |
Round-robin with health checks |
Monitoring |
Prometheus metrics for: - Token generation latency - Retrieval hit rate - Hallucination alerts |
Deployment Targets#
Multi-platform accessibility through:
Web Interface:
React.js frontend with response streaming
Interactive citation visualization
Session-based query history
CLI Tool:
Access to the hosted LLM through an Api Key
Configurable verbosity levels
Automated test script integration
Evaluation Framework#
The agentic evaluation system employs three specialized test agents:
Fact-Verification Agent:
Cross-references answers with source docs
Flags unsupported technical claims
Maintains accuracy heatmaps
Completeness Auditor:
Scores answer depth on:
API reference coverage
Troubleshooting steps
Example code relevance
Stress-Test Bot:
Generates adversarial queries
Measures failure modes
Identifies documentation gaps
Software#
Programming Languages: Python
ML Tools: PEFT, LoRA, Quantization
Frameworks: FastAPI, Hugging Face Transformers
Database: ChromaDB/Weaviate/Qdrant
Frontend: React
Deployment: Docker, Nginx, PYPI, Hugging Face Spaces
Version Control: Git, GitHub/GitLab
Hardware#
Development Boards: - BeagleBone AI-64 - BeagleY-AI
Cloud Services: - Hugging Face Spaces / Inference Endpoints - Vercel
Architecture and Diagrams#
These diagrams represent the workflow of the methods mentionned earlier.
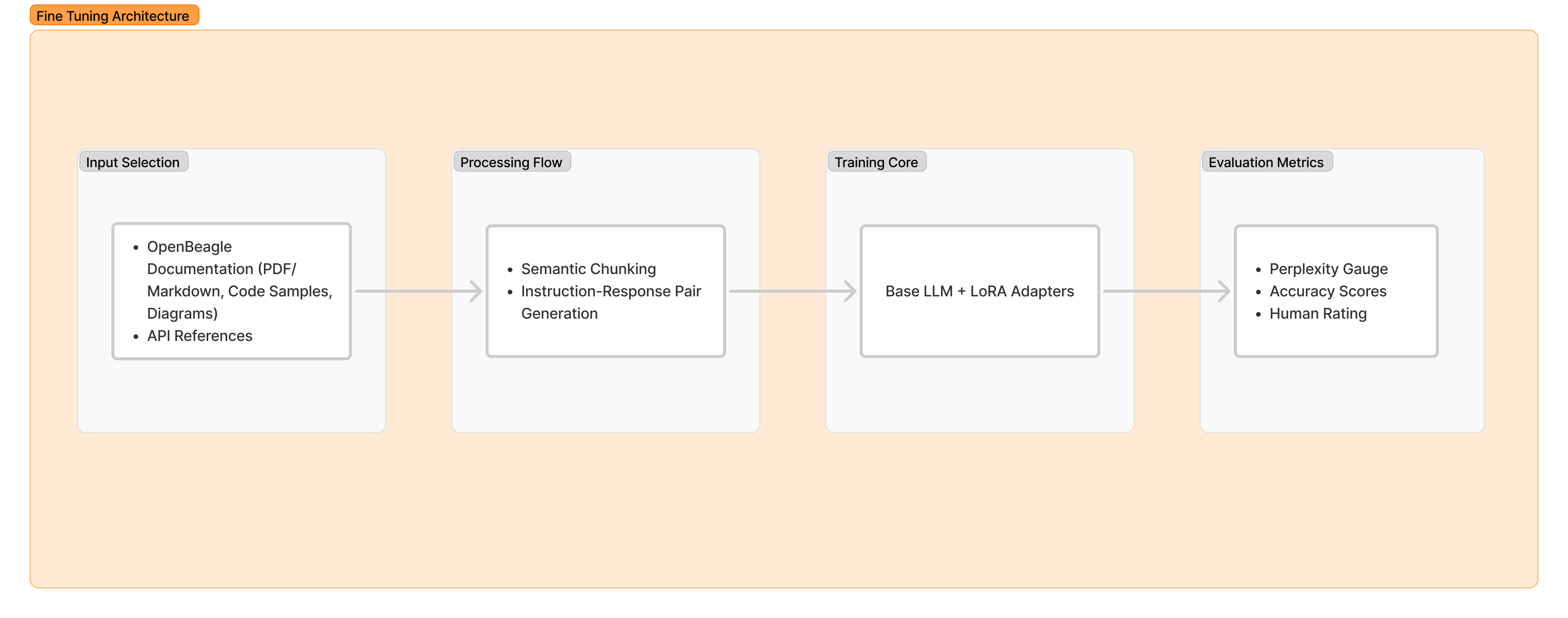
Fine-Tuning Architecture#
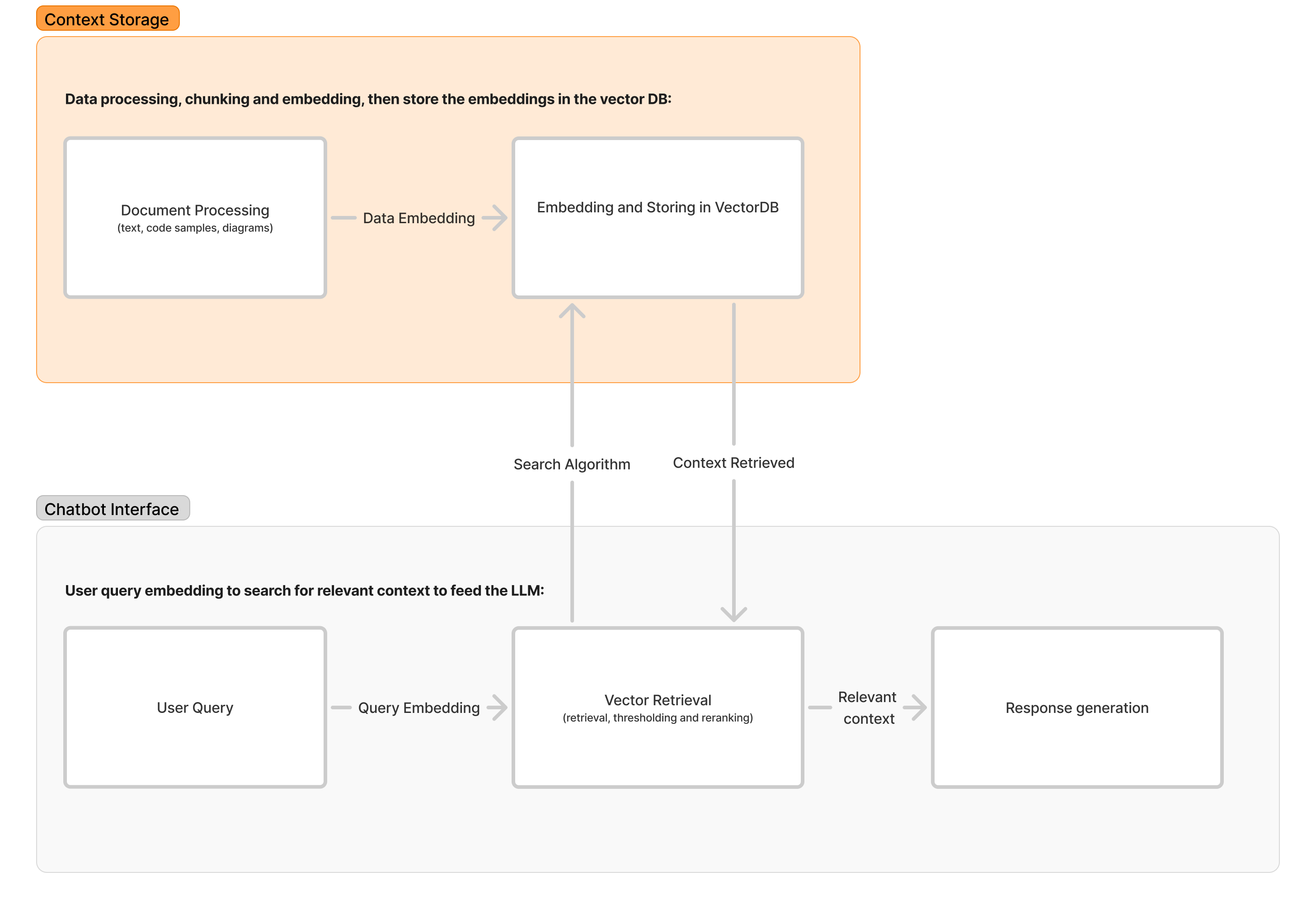
RAG Integration Pipeline#
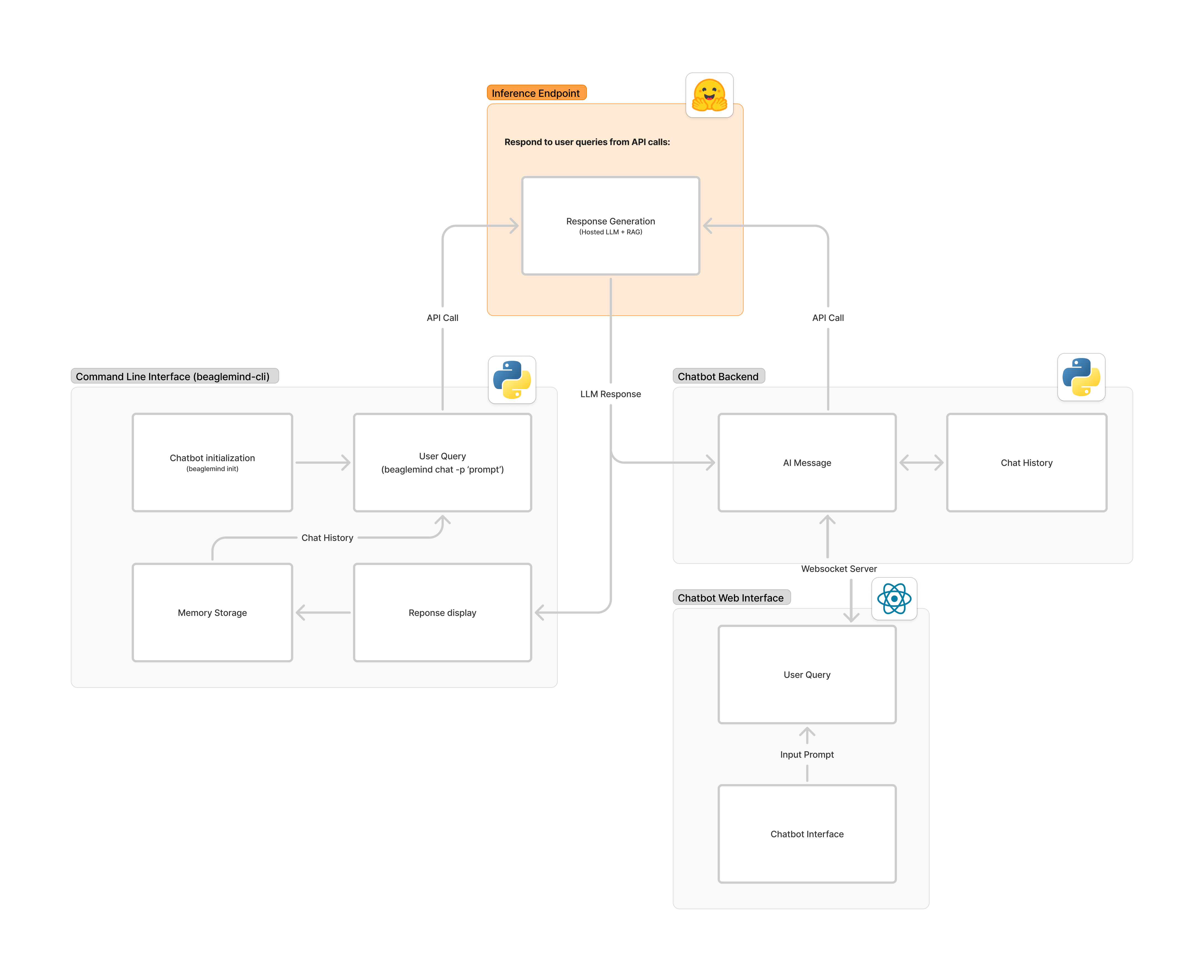
Deployment Structure#
Timeline#
Deadline |
Milestone |
Deliverables |
|---|---|---|
May 27 |
Coding Begins |
Finalize architecture diagrams |
June 3 |
M1: Foundation |
CLI prototype, Fine-tuning strategy doc |
June 17 |
M2: Data Preparation |
Curated dataset, Vector DB ready |
July 1 |
M3: Model Training |
Fine-tuned model on HF, Initial benchmarks |
July 8 |
Midterm Evaluation |
Working CLI with local inference |
July 22 |
M4: Agentic Evaluation |
Test agents implemented, Accuracy reports |
Aug 5 |
M5: Web Interface |
Websocket server, React frontend |
Aug 19 |
Final Submission |
Full documentation, Demo video |
Detailed Timeline#
Community Bonding (May 9 - May 26)#
Develop workflow diagrams:
Data collection pipeline
Fine-tuning process
RAG integration flow
Finalize model selection criteria
Establish evaluation metrics with mentor
Milestone 1: Foundation (June 3)#
CLI Prototype:
Basic question-answering interface
Chatbot using only RAG just to present the PoC
Provide helpful parameters like -h for help, -p for prompt and -l to refer to a log file
Simple evaluation script
Video demonstration:
Provide video demonstration
Present a proof of concept
Highlight that the actual solution will feature a hosted fine-tuned LLM and RAG to reduce hallucination
Fine-tuning Prep:
Document preprocessing scripts
Training environment setup
Milestone 2: Data Preparation (June 17)#
Document Processing:
Data formatting
Generate synthetic Q&A pairs
Convert all docs to clean Markdown
Extract code samples, diagrams, cicruit schemas and any resource that could help in the troubleshooting
Vector Database:
Implement chunking strategy
Test retrieval accuracy
Optimize embedding selection
Milestone 3: Model Training (July 1)#
Fine-tuning:
Training runs with different parameters
Loss/accuracy tracking
Quantization tests
Deployment:
HF Inference Endpoint setup
Performance benchmarks
Hallucination tests
Midterm Evaluation (July 8)#
Functional CLI with:
Model inference
Basic RAG integration
Accuracy metrics
Video demonstration
Mentor review session
Milestone 4: Agentic Evaluation (July 22)#
Evaluation Agents:
Fact-checking agent
Completeness evaluator
Hallucination detector
Automated Testing:
100-question test suite
Continuous integration setup
Performance dashboard
Milestone 5: Web Interface (Aug 5)#
Backend:
FastAPI websocket server
Dockerize the server
Async model loading
Rate limiting
Frontend:
React-based chat UI
Response visualization
Mobile responsiveness
Final Submission (Aug 19)#
Comprehensive documentation:
Installation guides
API references
Training methodology
5-minute demo video
Performance report
Benefit#
BeagleMind will provide:
24/7 documentation assistance
Reduced maintainer workload
Visualized technical answers
Accelerated debugging
Offline documentation access
Improved onboarding experience
Experience and Approach#
Personal Background#
As an Embedded Systems Engineering student with a passion for AI and robotics, I find the BeagleMind project perfectly aligns with my academic specialization and technical interests. My coursework in embedded systems, combined with self-study in Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG), has prepared me to bridge the gap between hardware documentation and AI-powered assistance.
Experience#
As an Embedded Systems Engineering student with AI specialization, I bring:
LENS Platform:
RAG Chatbot with Citations: Developed a retrieval-augmented chatbot that provides answers with detailed references, URL, page number, and File Name.
Chatautomation Platform:
Built multimodal data loaders (PDFs, images, audio)
Implemented voice interaction system (STT + LLM + TTS)
Developed WhatsApp/Instagram chatbot integrations
Orange Digital Center Internship:
Created MEPS monitoring system
Developed biogas forecast mode
Implemented agentic workflows for production reports
x2x Modality Project:
Hexastack Hackathon 1st place (Open source contribution)
Speech to Text for effortless communication
Text to Speech for improved accessibility
Image and Document Processing into text for smoother integration
Contingency#
If blockers occur:
Research documentation and source code
Seek community support (Discord/Forum)
Implement alternative approaches
Escalate to the mentor if unresolved
Misc#
Will comply with all GSoC requirements
Merge request will be submitted to BeagleBoard GitHub
Current demo available at bb-gsoc.fayez-zouari.tn | CLI GitHub Repo